Drawing Inference
Magnolia data
How can I visualize a single continuous variable?
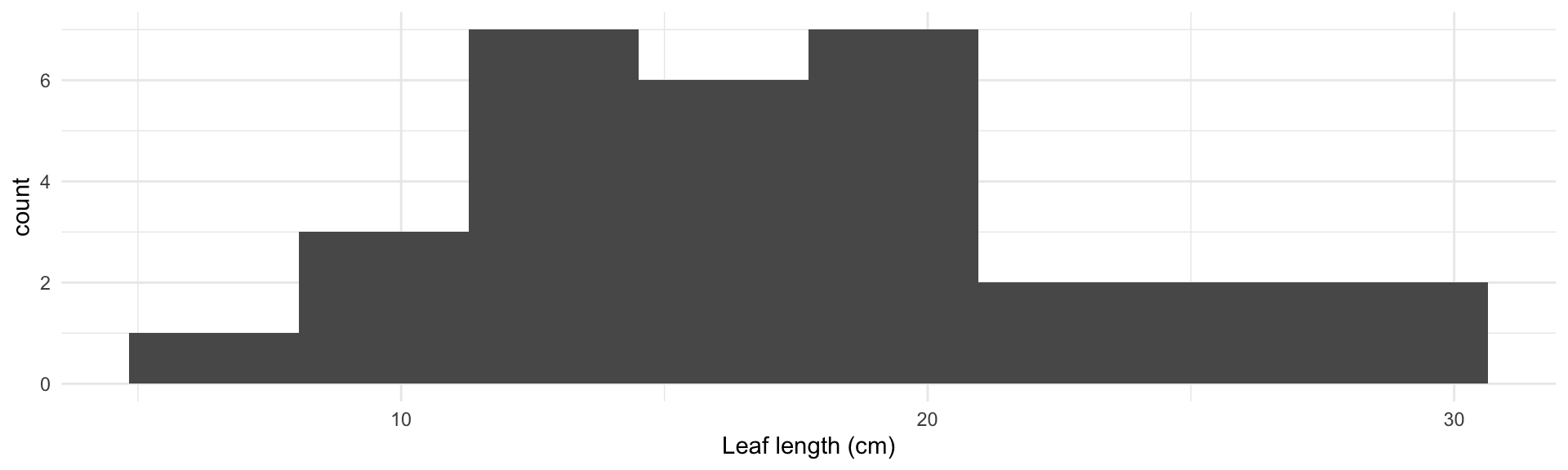
Magnolia data
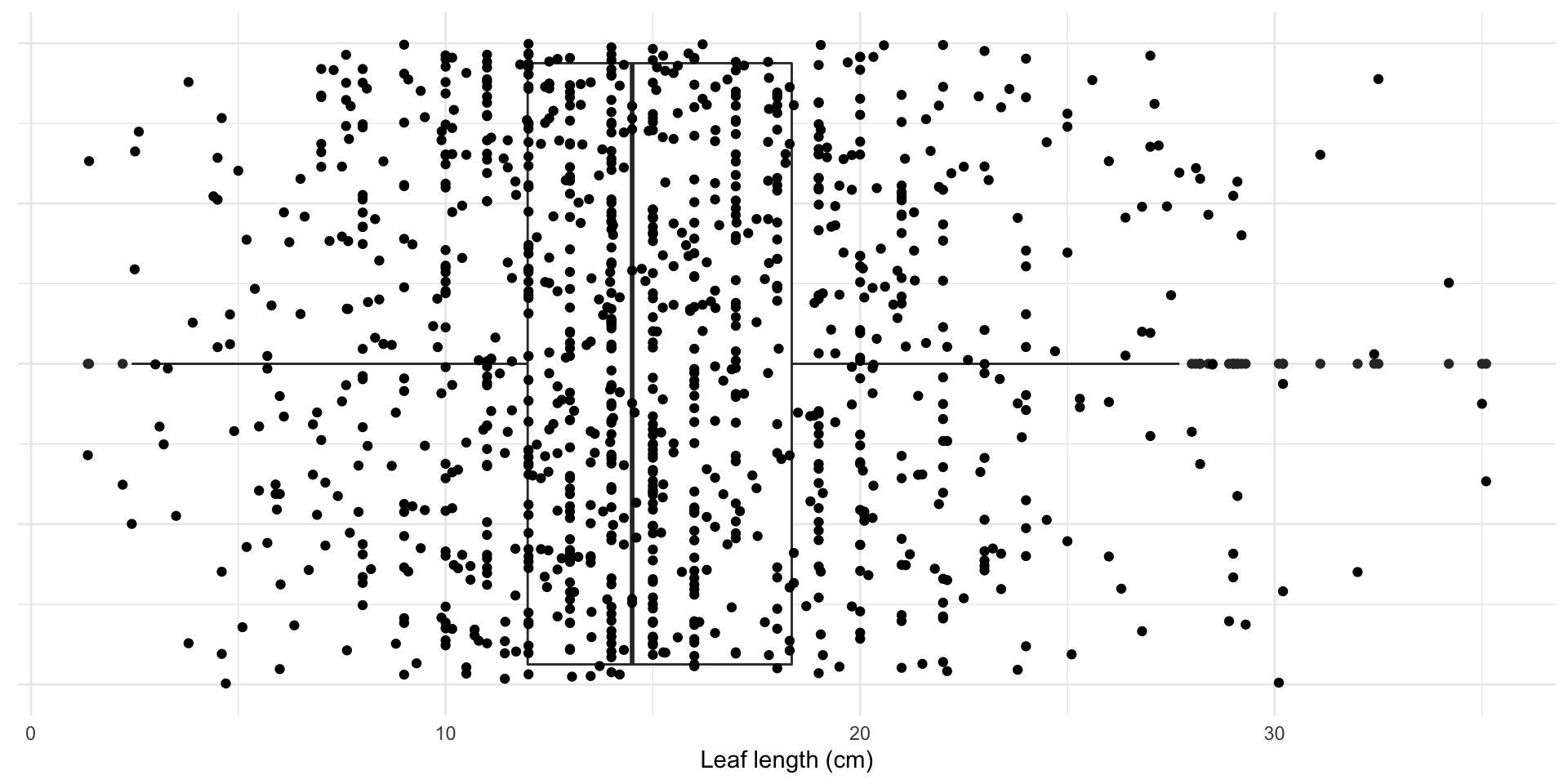
Magnolia data
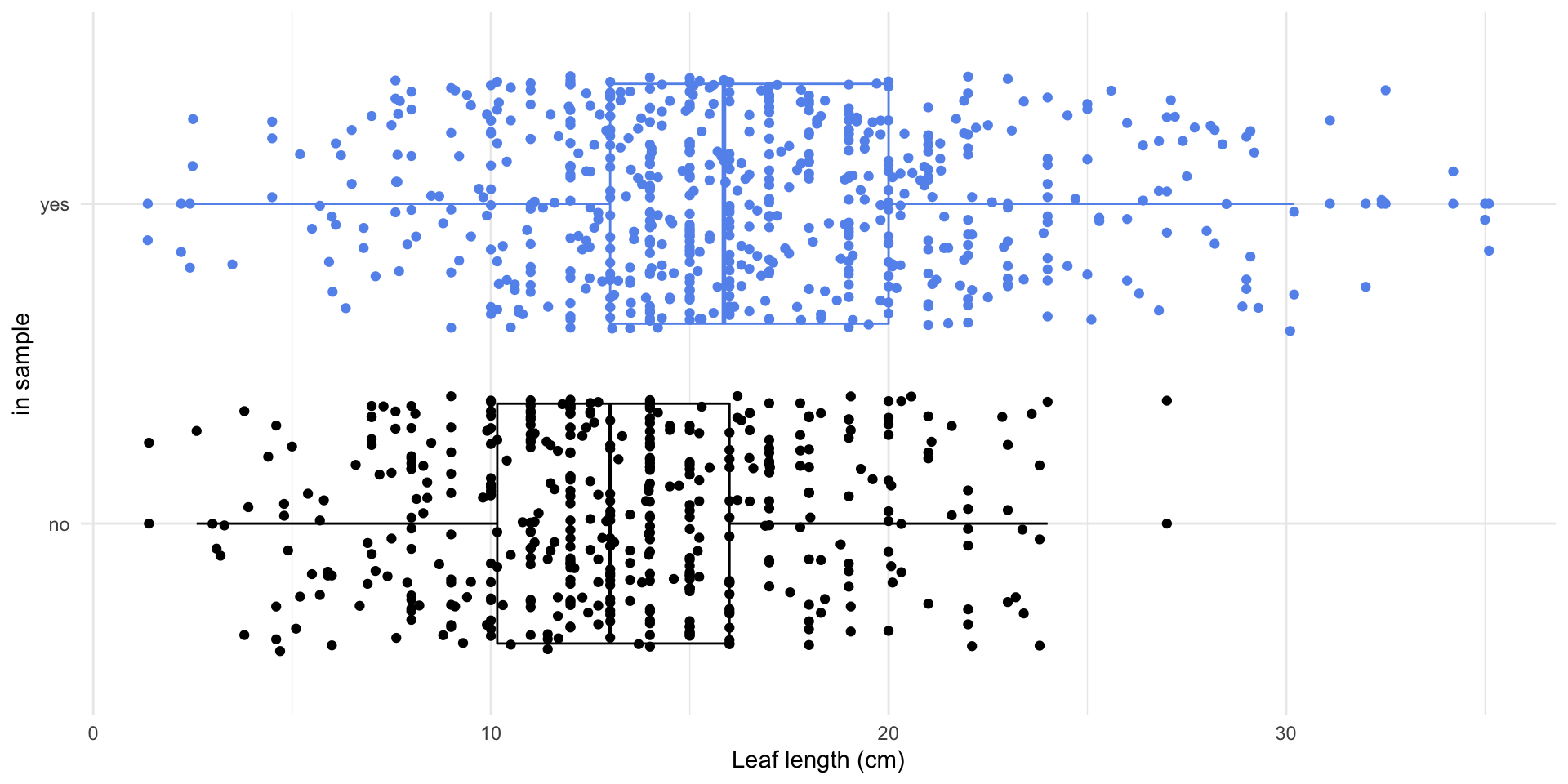
Code
set.seed(1)
ggplot(full_magnolia_data,
aes(x = leaf_length, y = 1)) +
geom_boxplot() +
geom_jitter() +
geom_jitter(data = magnolia_data, color = "cornflower blue", size = 3) +
labs(x = "Leaf length (cm)") +
theme(axis.title.y = element_blank(),
axis.text.y = element_blank(),
axis.ticks.y = element_blank())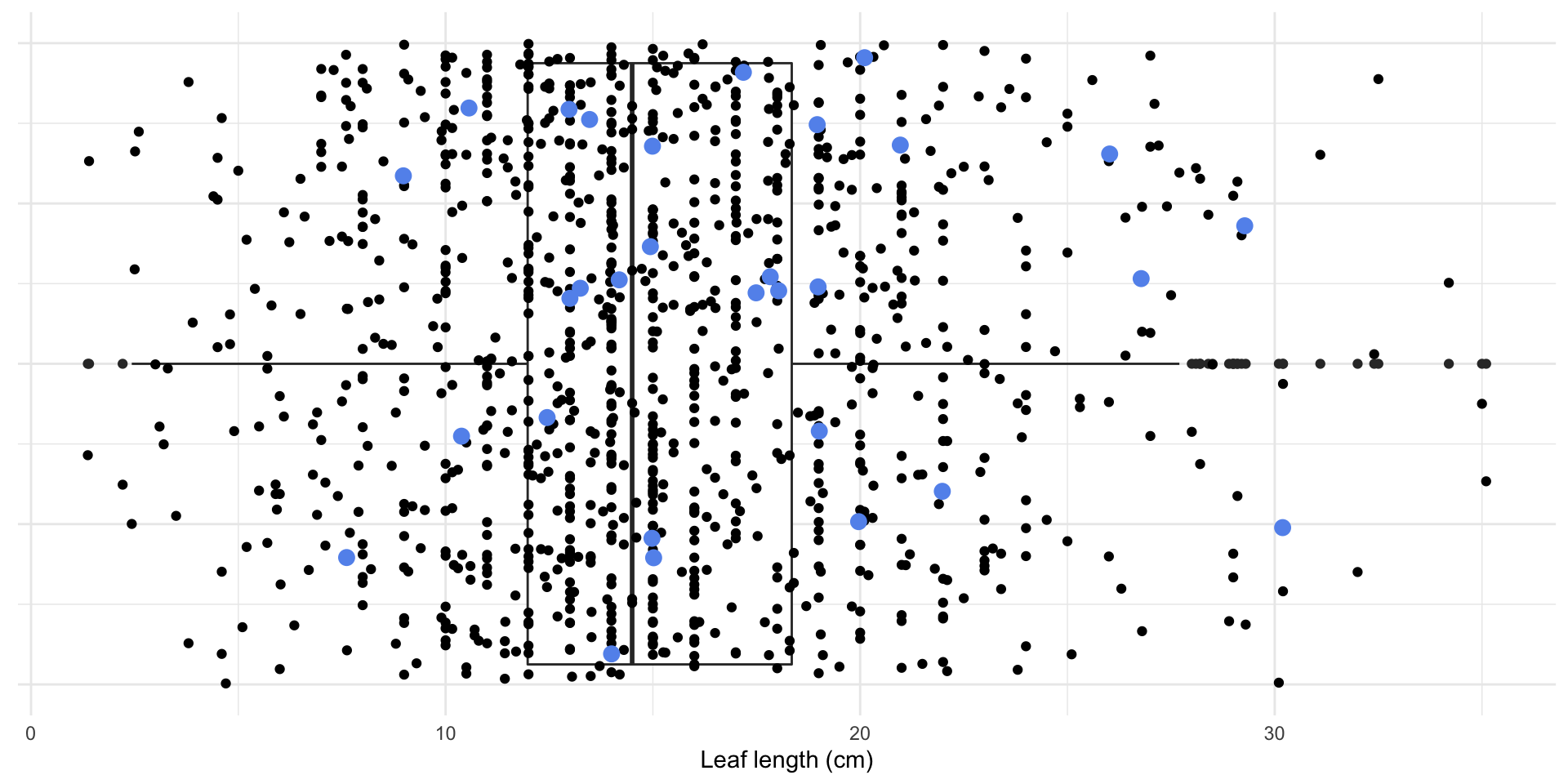
Magnolia data
Application Exercise
- Open
appex-08.qmd - Calculate the \(t^*\) value for your confidence interval
- Calculate the confidence interval “by hand” using the \(t^*\) value from exercise 2 and the mean and standard error from the previous application exercise
- Calculate the confidence interval using the
confintfunction - Interpret this value
05:00