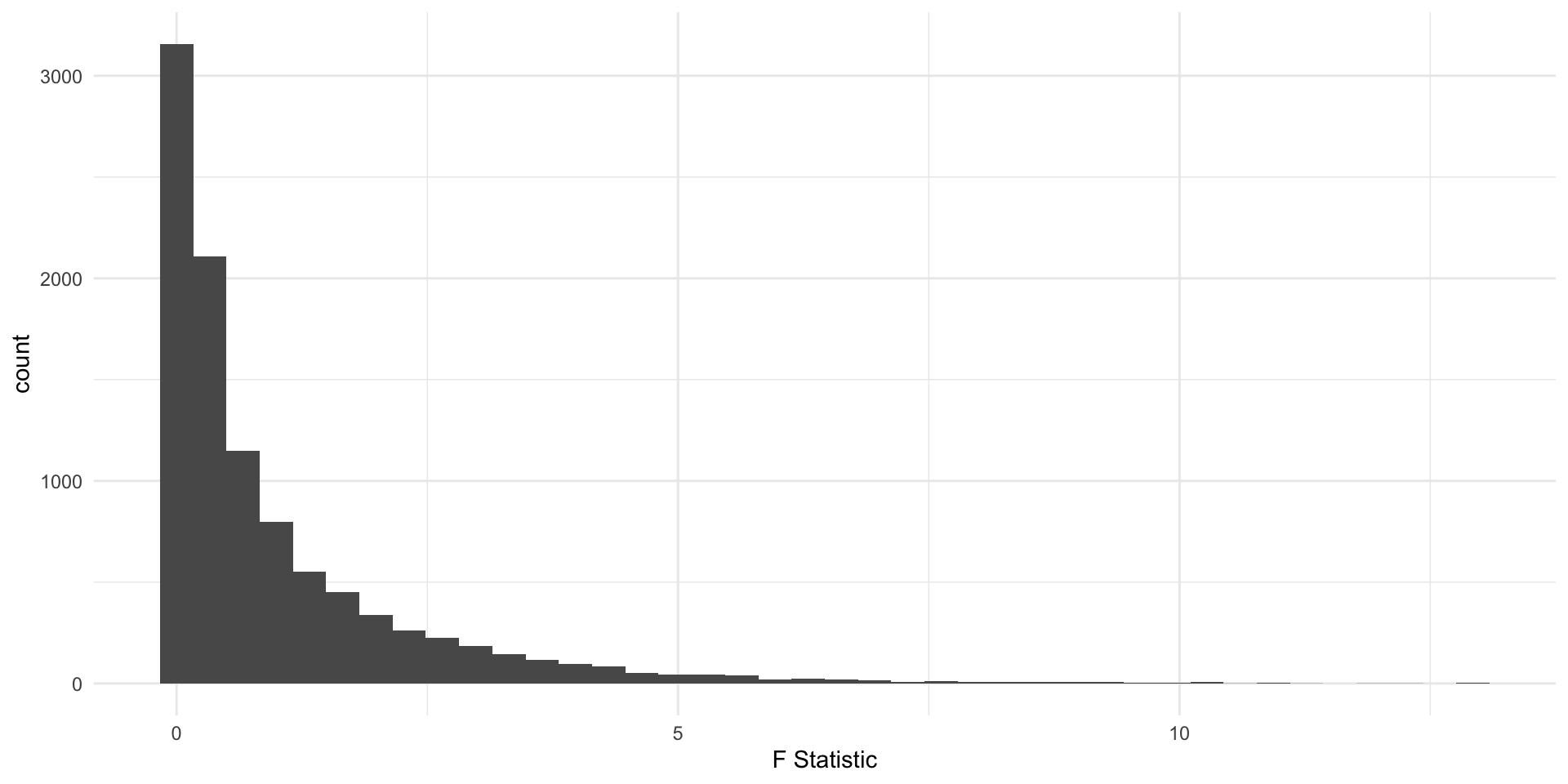
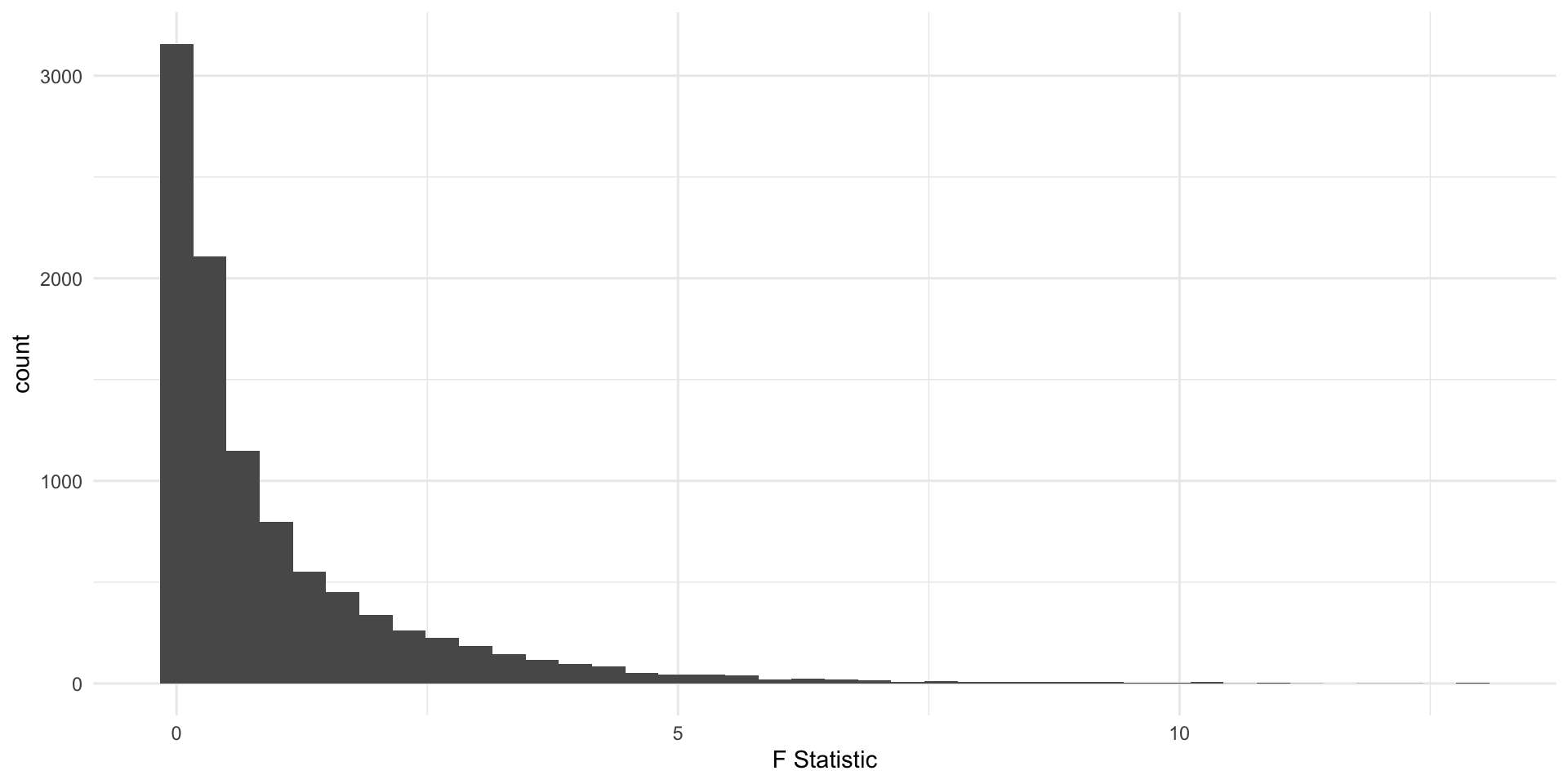
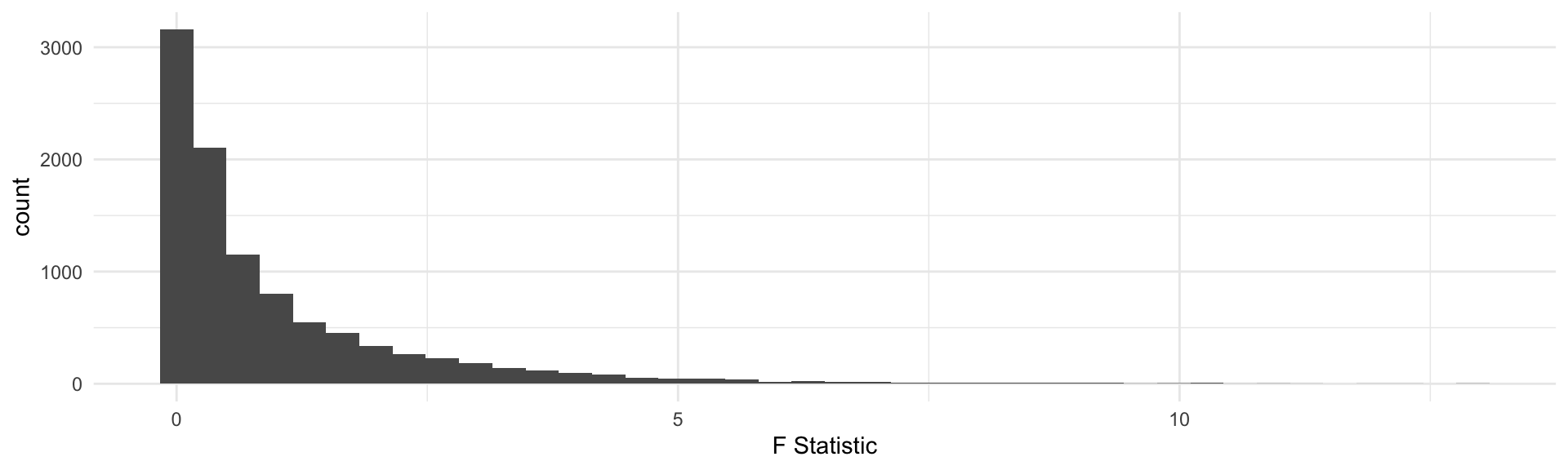
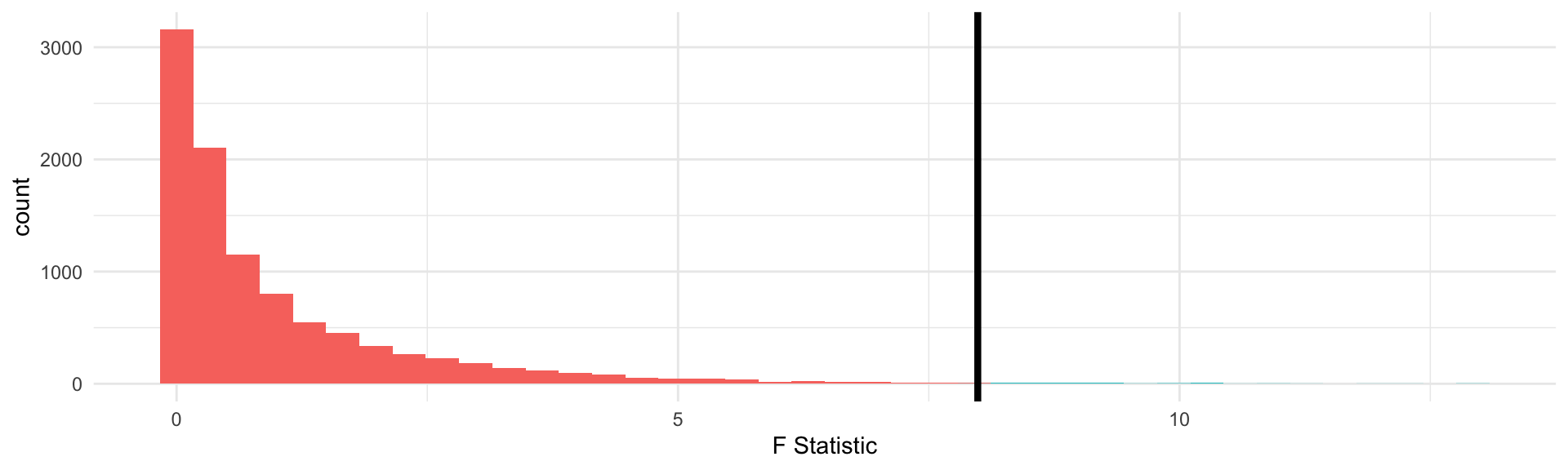
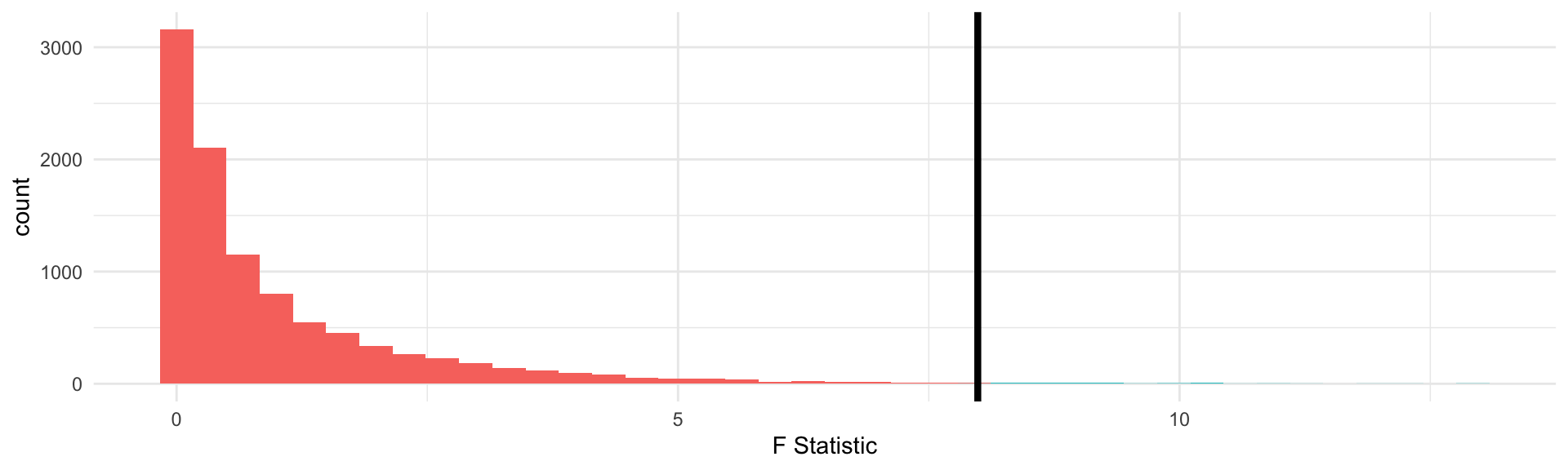
The p-value calculates values “as extreme or more extreme”, in the t-distribution “more extreme values”, defined as farther from 0, can be positive or negative. Not so for the F!
Example
anova(mod)
Analysis of Variance Table
Response: leaf_length
Df Sum Sq Mean Sq F value Pr(>F)
leaf_width 1 226.7 226.71 7.9882 0.005707 **
Residuals 98 2781.2 28.38
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
summary(mod)
Call:
lm(formula = leaf_length ~ leaf_width, data = magnolia_data)
Residuals:
Min 1Q Median 3Q Max
-12.4544 -3.2196 -0.0287 3.1761 12.6086
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 11.8362 1.3956 8.481 2.36e-13 ***
leaf_width 0.4386 0.1552 2.826 0.00571 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.327 on 98 degrees of freedom
Multiple R-squared: 0.07537, Adjusted R-squared: 0.06593
F-statistic: 7.988 on 1 and 98 DF, p-value: 0.005707
Notice the p-value for the F-test is the same as the p-value for the \(\hat\beta_1\) t-test
This is always true for simple linear regression (with just one \(x\) variable)
What is the F-test testing?
anova(mod)
Analysis of Variance Table
Response: leaf_length
Df Sum Sq Mean Sq F value Pr(>F)
leaf_width 1 226.7 226.71 7.9882 0.005707 **
Residuals 98 2781.2 28.38
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
null hypothesis: the fit of the intercept only model (with \(\hat\beta_0\) only) and your model (\(\hat\beta_0 + \hat\beta_1x\)) are equivalent
alternative hypothesis: The fit of the intercept only model is significantly worse compared to your model
When we only have one variable in our model, \(x\), the p-values from the F and t tests are going to be equivalent
Relating the F and the t
anova(mod)
Analysis of Variance Table
Response: leaf_length
Df Sum Sq Mean Sq F value Pr(>F)
leaf_width 1 226.7 226.71 7.9882 0.005707 **
Residuals 98 2781.2 28.38
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
summary(mod)
Call:
lm(formula = leaf_length ~ leaf_width, data = magnolia_data)
Residuals:
Min 1Q Median 3Q Max
-12.4544 -3.2196 -0.0287 3.1761 12.6086
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 11.8362 1.3956 8.481 2.36e-13 ***
leaf_width 0.4386 0.1552 2.826 0.00571 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.327 on 98 degrees of freedom
Multiple R-squared: 0.07537, Adjusted R-squared: 0.06593
F-statistic: 7.988 on 1 and 98 DF, p-value: 0.005707
2.826^2
[1] 7.986276
Application Exercise
Open appex-11.qmd
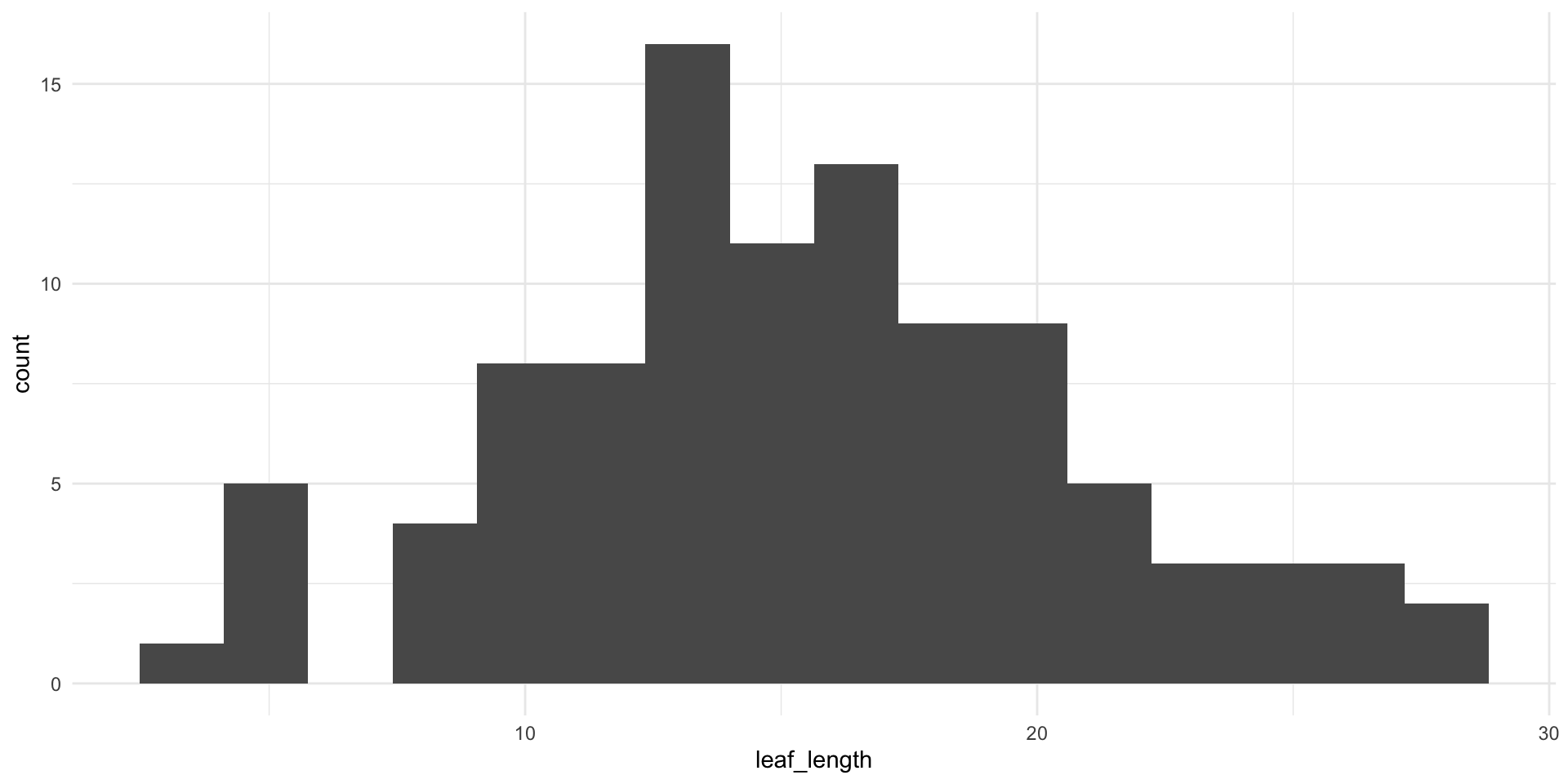
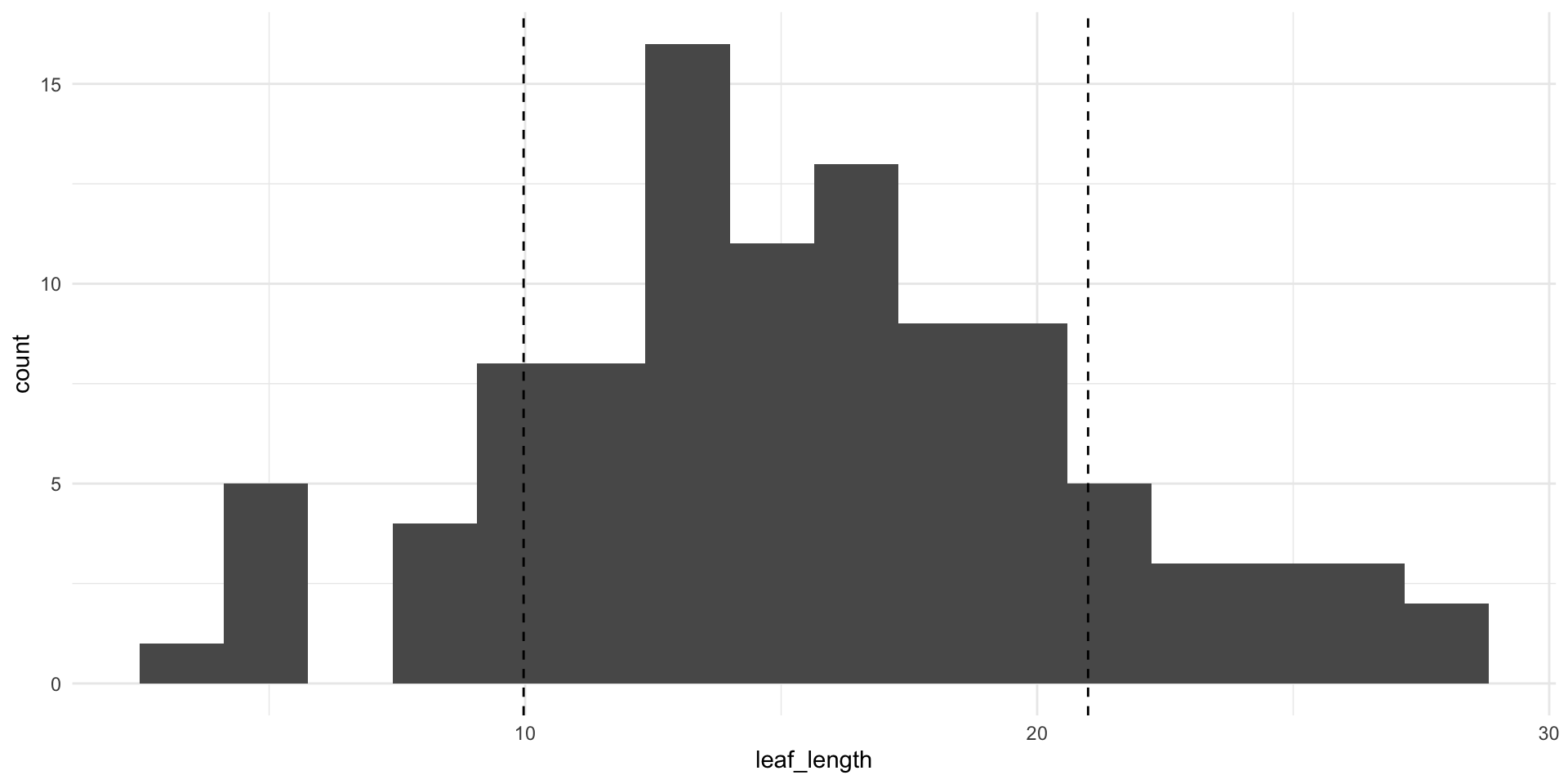
Using your magnolia data, predict leaf length from leaf width
What are the degrees of freedom for the: Sum of Squares Total, Sum of Squares Model, Sum of Squares Errors
Calculate the following quantities: Sum of Squares Total, Sum of Squares Model, Sum of Squares Errors
Calculate the F-statistic for the model and the p-value
What is the null hypothesis? What is the alternative?