When the goal is inference how do we choose what to include in our model?
We need to understand the theoretical relationship between the explanatory variable we are interested in, the outcome variable we are interested in, and any confounders.
There is not a statistical test we can do to test whether we have included all relevant variables
Selecting variables
When the goal is prediction we can use the metrics we learned about last class to compare models
But how do we choose what to put in those models to begin with?
What if we look at every combination of all available variables?
Multicollinearity
One concern with including every potential combination of all variables is that we may include variables that are highly correlated
In the extreme case, if one predictor has an exact linear relationship with one ormore other predictors in the model, the least squares process does not have a unique solution
d <-tibble(x1 =rnorm(100),x2 =rnorm(100),x3 =3* x1 +4* x2,y =rnorm(100))lm(y ~ x1 + x2 + x3, data = d)
Call:
lm(formula = y ~ x1 + x2 + x3, data = d)
Coefficients:
(Intercept) x1 x2 x3
0.12514 0.03661 -0.02821 NA
Multicollinearity
In the less extreme case where the variables are not perfect linear combinations of each other, but still highly correlated, including all variables could inflate your variance
Call:
lm(formula = y ~ x1 + x2 + x3, data = d)
Residuals:
Min 1Q Median 3Q Max
-2.58201 -0.52738 0.00281 0.65058 1.82364
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.05273 0.10065 0.524 0.602
x1 0.94204 0.11169 8.434 3.4e-13 ***
x2 -3.23987 3.88095 -0.835 0.406
x3 1.04623 0.97118 1.077 0.284
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.998 on 96 degrees of freedom
Multiple R-squared: 0.6144, Adjusted R-squared: 0.6024
F-statistic: 51 on 3 and 96 DF, p-value: < 2.2e-16
Code
summary(lm(y ~ x1 + x2, data = d))
Call:
lm(formula = y ~ x1 + x2, data = d)
Residuals:
Min 1Q Median 3Q Max
-2.48809 -0.54939 -0.05717 0.65489 1.81422
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.05538 0.10070 0.550 0.584
x1 0.94425 0.11177 8.448 2.96e-13 ***
x2 0.93946 0.10480 8.964 2.31e-14 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9989 on 97 degrees of freedom
Multiple R-squared: 0.6098, Adjusted R-squared: 0.6017
F-statistic: 75.79 on 2 and 97 DF, p-value: < 2.2e-16
Here, I am focusing on the \(\hat\beta\) and it’s standard error, is this an inference focus or prediction?
Multicollinearity
For prediction we care about multicollinearity if we are trying to fit a parsimonious model. We can potentially remove predictors that are highly correlated with other variables since they don’t add much additional information
To determine how correlated a predictor is with all of the other variables included, we can examine the variance inflation factor
\[VIF_i = \frac{1}{1-R_i^2}\]
\(R_i^2\) is the \(R^2\) value from the model used to predict \(X_i\) from all of the remaining predictors.
Variance inflation factor
summary(lm(x1 ~ x2 + x3, data = d))
Call:
lm(formula = x1 ~ x2 + x3, data = d)
Residuals:
Min 1Q Median 3Q Max
-2.30129 -0.60350 0.01765 0.58513 2.27806
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.10841 0.09083 1.194 0.236
x2 -0.63849 3.52738 -0.181 0.857
x3 0.15960 0.88270 0.181 0.857
Residual standard error: 0.9073 on 97 degrees of freedom
Multiple R-squared: 0.0003379, Adjusted R-squared: -0.02027
F-statistic: 0.01639 on 2 and 97 DF, p-value: 0.9837
1/ (1-0.0003379)
[1] 1.000338
summary(lm(x2 ~ x1 + x3, data = d))
Call:
lm(formula = x2 ~ x1 + x3, data = d)
Residuals:
Min 1Q Median 3Q Max
-0.066055 -0.016015 0.000616 0.011195 0.073233
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.0006617 0.0026323 -0.251 0.802
x1 -0.0005288 0.0029217 -0.181 0.857
x3 0.2501524 0.0006856 364.880 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.02611 on 97 degrees of freedom
Multiple R-squared: 0.9993, Adjusted R-squared: 0.9993
F-statistic: 6.657e+04 on 2 and 97 DF, p-value: < 2.2e-16
1/ (1-0.9993)
[1] 1428.571
A rule of thumb is that we suspect multicollinearity if VIF > 5
We could drop one of the highly correlated predictors from our model
Choosing predictors
We could try every combination of all variables
This could get computationally expensive - you are fitting \(2^k\) models (so if you have 10 predictors, that is 1,024 models you are choosing between, yikes!)
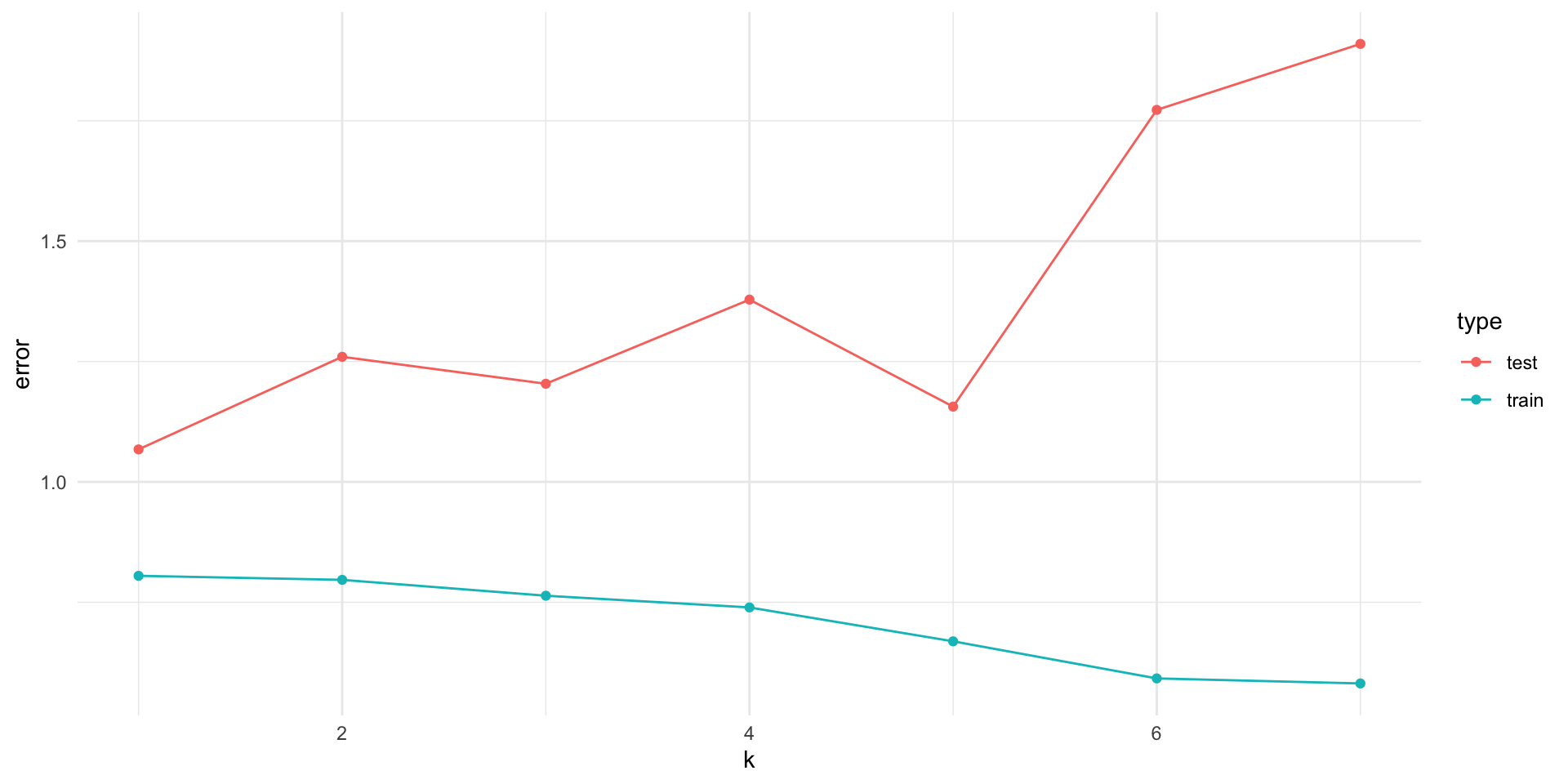
Another issue with trying every possible combination of models is you could overfit your model to your data – that is, the model might fit very well to these particular observations, but would do a poor job predicting a new sample.
get_error <-function(k) { train <- d_samp1 %>%sample_n(19) test <- d_samp1 %>%anti_join(train, by =c("x1", "x2", "x3", "x4", "x5", "x6", "x7", "y")) form <-as.formula(glue("y ~ {glue_collapse(glue('x{1:k}'), sep = ' + ')}" )) mod <-lm(form, data = train)tibble(error =c(mean(residuals(mod)^2), mean((test$y -predict(mod, test))^2)),type =c("train", "test"),k = k )}set.seed(1)err <-map_df(rep(1:7, each =100), get_error) err %>%group_by(k, type) %>%summarise(error =mean(error)) %>%ggplot(aes(x = k, y = error, color = type)) +geom_point() +geom_line()
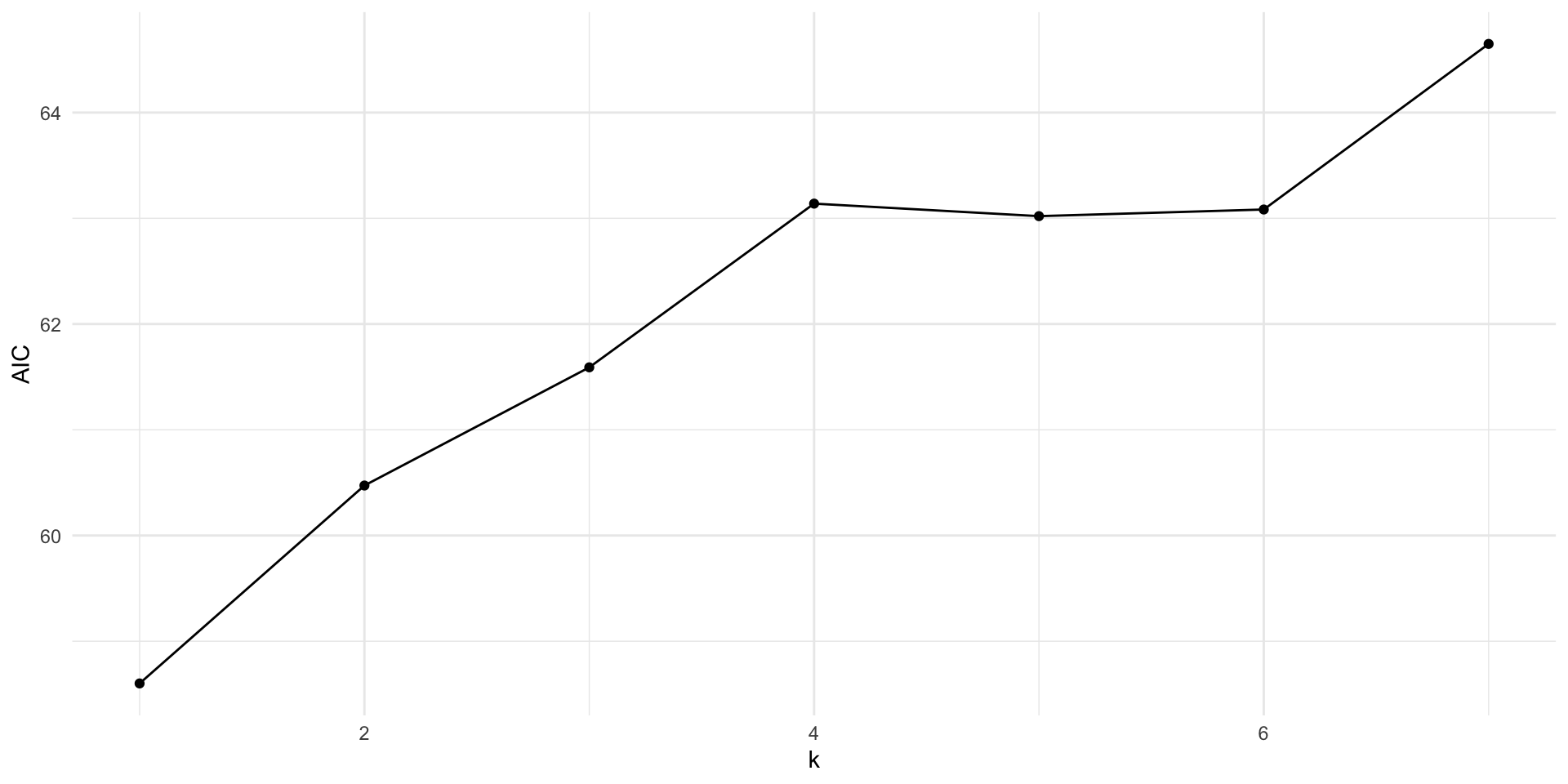
AIC
It turns out in the case of linear regression, AIC mimics the choice from LOOCV so you don’t have to learn how to do this complicated method!
Code
get_aic <-function(k) { form <-as.formula(glue("y ~ {glue_collapse(glue('x{1:k}'), sep = ' + ')}" )) mod <-lm(form, data = d_samp1)tibble(AIC =AIC(mod),k = k )}err <-map_df(1:7, get_aic)err %>%ggplot(aes(x = k, y = AIC)) +geom_point() +geom_line()
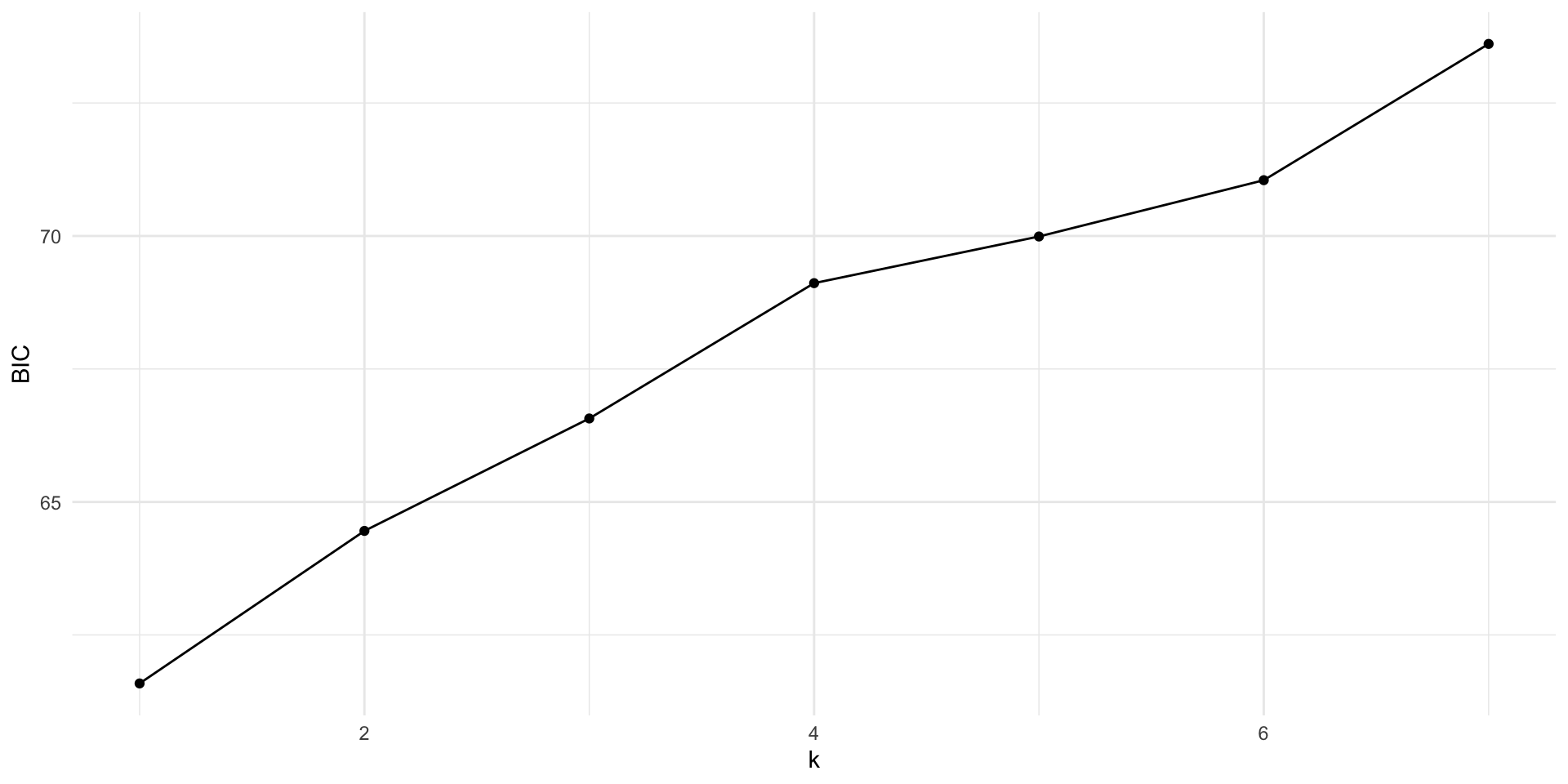
BIC
BIC is equivalent to leave-\(k\)-out cross validation (where \(k = n[1-1/log(n)-1])\)) for linear models, so we can also use this metric without having to code up the complex cross validation!
Code
get_bic <-function(k) { form <-as.formula(glue("y ~ {glue_collapse(glue('x{1:k}'), sep = ' + ')}" )) mod <-lm(form, data = d_samp1)tibble(BIC =BIC(mod),k = k )}err <-map_df(1:7, get_bic)err %>%ggplot(aes(x = k, y = BIC)) +geom_point() +geom_line()
Big picture
inference
we need to use our theoretical understanding of the relationship between variables in order to properly select variables to include in our model
Big picture
inference
we need to use our theoretical understanding of the relationship between variables in order to properly select variables to include in our model
prediction
Choose a set of predictors to assess
Use a metric that balances parsimony with goodness of fit (\(R^2_{adj}\), AIC, BIC) to select the model
Best practice is to fit the model on one set of data and test it on another (using something like Leave-one-out cross validation), but it turns out AIC and BIC mimic this for linear regression (yay!) so we can reliably use these metric even when not splitting our data